Advanced Celery: mastering idempotency, retries & error handling


The difference between a working async task and a production-ready one often comes down to how it handles failure. While any developer can write code that works in perfect conditions, crafting tasks that gracefully handle network outages, race conditions, and partial failures requires a deeper understanding of distributed systems.
If you've got some experience under your belt, this post is tailored just for you. But if you're new to Celery, I'd recommend checking out my previous post for a solid foundation before diving into this one.
You may also like: Vinta promoted this workshop on how to boost Django projects with Celery.
Async tasks are like the heartbeat of modern applications, ensuring everything runs smoothly behind the scenes. The real challenge, however, isn't just getting them up and running – it's what to do when things go awry. How do you handle unexpected bugs? Recover from sudden shutdowns? And what's the game plan when external services throw you a curveball?
In this post, I'll unveil the best practices to help you thwart errors, mitigate risks, simplify debugging, boost robustness, and enhance recoverability. Though integrations often bring their fair share of headaches, the best way to avoid them is by writing code that can gracefully tackle these challenges.
But before we dive into the nitty-gritty of code, let's clarify two crucial concepts: Idempotency and Atomicity.
What is Idempotency?
In mathematics and computer science, idempotency refers to a remarkable property of certain operations. It's all about the idea that you can apply these operations multiple times. The result remains unchanged beyond the initial application.
It is the math equivalent of multiplying a number by zero or one. No matter how often you do it, the result stubbornly stands.
For instance, consider the simple operation of multiplying:
It's the same story with multiplication by one:
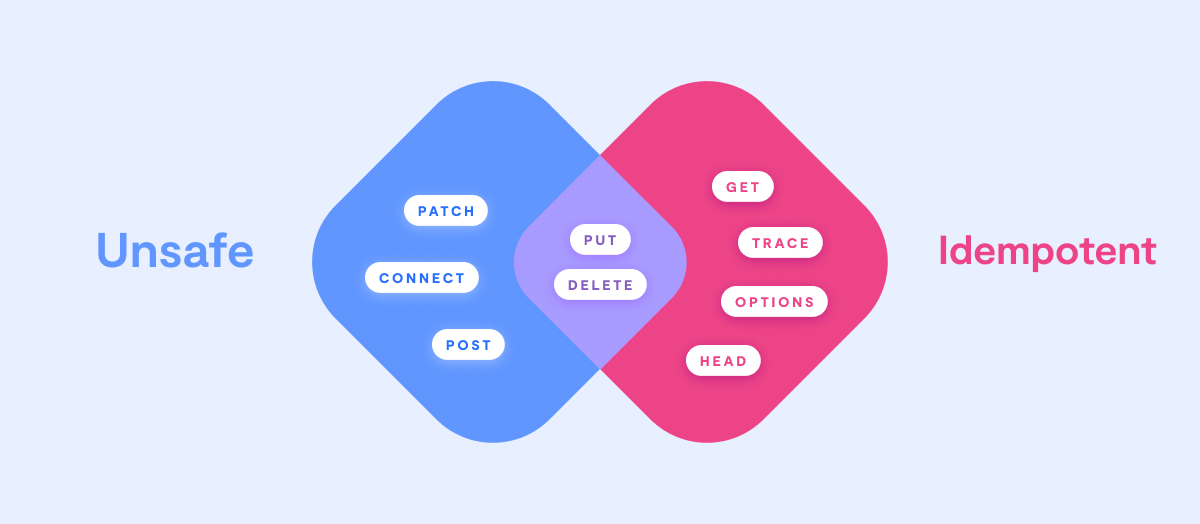
Now, let's shift our focus to the realm of HTTP, where we're faced with different methods, each with its own idempotent or non-idempotent nature.
- GET: When you GET a resource, it should not produce any changes to it, making it an idempotent operation.
- POST: POST is commonly used for resource creation. Unlike GET, it's generally not idempotent. Every POST request may change the state of the application, meaning whoever uses POST shouldn't count with its idempotency.
- PUT: This is a prime example of an idempotent operation that's not simply a read. The first PUT request produces a change in the state, but repeating the same request won't introduce any further changes. It's like a create-update operation in the same method.
- DELETE: It's a bit of a gray area. From the application's state perspective, it's idempotent. However, from the HTTP response perspective, the first call might return a 204 status code, while subsequent calls might return a 404. So, its idempotency depends on your viewpoint.
What is Atomicity?
Atomicity is a concept with roots in database operations and various other contexts. It's about an indivisible and irreducible series of operations in which either everything occurs successfully or nothing changes.
Consider a scenario where you have a Celery task called update_data. In this task, the user's status is set to updated, then saved, followed by a request to Facebook, and finally, the user's name is updated and saved again. Sounds like a logical sequence, right? However, it's not atomic.
If that Facebook request fails, you're left with an inconsistent database state - a user with status=updated but an outdated name. To make this atomic, the right approach is first to make the Facebook request and then simultaneously update the user's status and name.
Here's the improved task:
Now, it's atomic, ensuring that either everything succeeds or everything fails.
Another strategy to enhance atomicity is to keep your tasks short. Consider an example of sending newsletters to all users within a single task. If one fails, the entire task will fail, too, resulting in partial email delivery and no information about who missed out.
Instead of doing it all in one task, you can delegate the email sending to another task:
This refactored approach ensures that if an email fails to send, it only affects one user. Moreover, it's easier to identify and rerun the failed tasks. However, it's essential to be mindful of task granularity, as overly fine-grained tasks can impact performance due to Celery's overhead on each task execution.
Now that we've established a solid grasp of idempotency and atomicity, let's explore strategies and Celery-specific features to enhance our async task writing skills further.


Retrying for Resilience
Earlier on, we emphasized the need to acknowledge that tasks are prone to errors. This is where the concepts of Idempotency and Atomicity come into play: tasks that embody both these principles can be rerun multiple times without any risk of introducing inconsistencies.
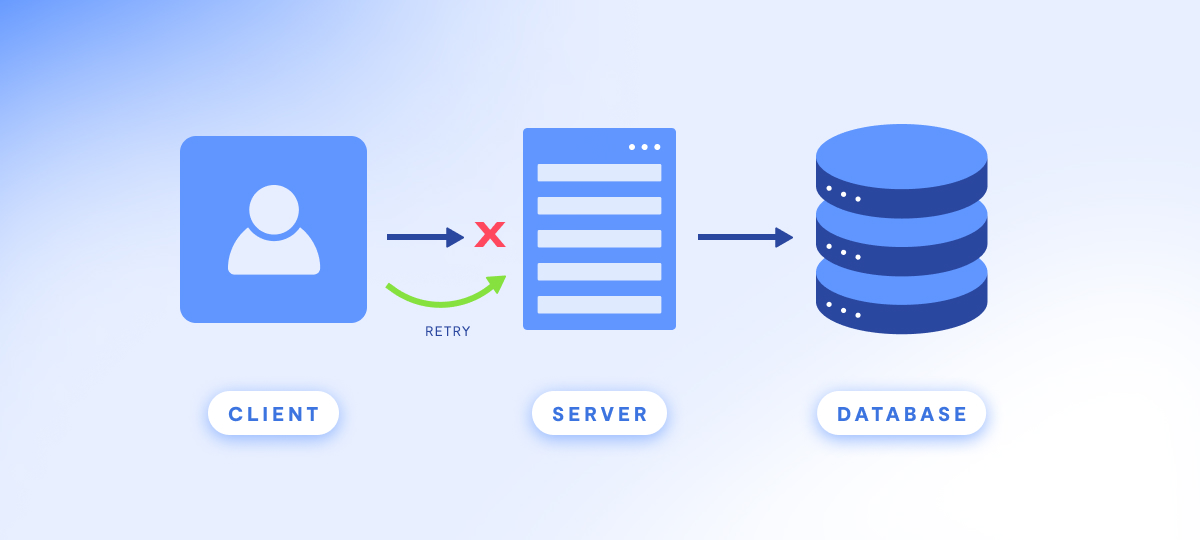
Now, let's delve into the primary reasons tasks might fail. There are two main culprits: bugs in your code and hiccups in your interactions with external systems.
When it comes to bugs in your code, you're in control. You can deploy a fix and manually rerun the task to resolve the issue. However, when the trouble comes from external systems behaving unexpectedly, a different strategy is required. In such cases, it's beneficial to keep retrying the task until the external service gets back on track.
For this purpose, Celery provides a handy retry functionality that can be employed within a task. This allows you to define the situations in which the task should be automatically re-executed.
Here's a practical example:
In this example, we attempt to fetch a user's likes from Facebook using the Facebook Tapioca client. If the operation fails, we introduce a 10-second delay and then retry it up to 4 times.
If your tasks adhere to the principles of idempotency and atomicity, you can confidently use the retry method as many times as necessary until the task succeeds. However, be cautious, as retrying in non-idempotent and non-atomic tasks may result in inconsistencies or worse side effects, such as flooding your users with repeated emails.
When retrying tasks, there are a few considerations to keep in mind. In some cases, the failure might be due to an external service, such as the Facebook API, being down. In such situations, it's wise to implement a backoff mechanism, giving the external APIs some time to recover.
Furthermore, extending the interval between retries by an exponential amount can enhance the odds of completing the task successfully on the next attempt. Introducing a random factor to the retry delay can also help prevent overwhelming the external system.
You can manually implement this kind of backoff using the countdown argument in the retry method, as shown in the code snippet below:
Those utilizing Celery 4 or higher can streamline their code using the autoretry_for parameter and retry_backoff. The second one is available starting from Celery 4.1 and automatically implements exponential backoff when errors occur.
Handling Late Acknowledgments
A crucial aspect to be aware of is acks_late. By default, Celery marks a task as "done" before finishing it, right after the worker gets it to execute it. This prevents a task from running twice in the event of an unexpected worker shutdown, a sound default behavior for non-idempotent tasks.
However, if you're actively designing idempotent and atomic tasks, enabling the task_acks_late setting won't harm your application. It will enhance its robustness against worker shutdowns caused by problems like cloud container restarts, deployments, or even random bugs in Celery or Python. You can also configure acks_late on a per-task basis.
Time Limiting for Performance
Another common issue in async tasks is dealing with tasks that run for extended durations due to bugs or network latency. To prevent these lengthy tasks from adversely affecting your application's performance, you can set a task_time_limit. Celery will gracefully interrupt a task if it exceeds the specified time limit.
If you need to perform some recovery operations before the task is terminated, you can also set a task_soft_time_limit. When this soft time limit is reached, Celery raises a SoftTimeLimitException, allowing you to perform cleanup operations.
Here's an example of how to implement task time limits:
Vigilant Monitoring for Robustness
Monitoring async tasks requires a different level of vigilance compared to web applications. While web application errors are often noticeable because they lead to visible issues, async tasks don't always have such an immediate impact on the user experience. This highlights the importance of robust monitoring to catch errors early, preventing them from snowballing into major problems.
Comprehensive logging is essential, starting with the basics. Proper logging provides a detailed record of what transpired during task execution, aiding in debugging. However, exercise caution to avoid exposing sensitive information in logs, as it can pose a security and privacy issue to your users' data. Logging is a general recommendation for all applications, but it's particularly critical for tasks, as there's no user interface for debugging.
Here's an example of setting up logging in a Celery task:
Beyond logging, ensuring your team is promptly notified when tasks fail is imperative. Tools like Sentry can be easily integrated with Django and Celery to facilitate error monitoring. Integration with communication platforms like Slack ensures you receive notifications whenever something goes awry.
However, it's crucial to fine-tune the notification settings to avoid excessive false positives, which might lead your team to overlook real errors. Establish a straightforward process for handling errors and ensure they are prioritized and included in your backlog whenever new ones arise.
Apart from these strategies, many other tools are available for monitoring tasks. Two examples commonly used in various projects are:
- Flower: This tool enables live monitoring of Celery tasks, allowing you to inspect running tasks and track completed ones. It's a standalone application and particularly beneficial for larger systems.
- django-celerybeat-status: This tool integrates with the Django admin interface, providing a view of all scheduled tasks along with their next Estimated Time of Arrival (ETA). This can help reduce confusion and errors when working with crontab schedules.
Testing and Debugging Made Easier
Testing and debugging async tasks can be more challenging than testing and debugging typical web applications. However, there are strategies to mitigate these challenges. One such strategy is to use the task_always_eager setting.
When this setting is enabled (set to True), calling delay or apply_async will run the task synchronously rather than delegating it to a worker. This approach simplifies local debugging and facilitates automated testing. Note that it's essential to ensure that task_always_eager is not activated in the production environment.
Conclusion
In the end, building resilient async tasks is more art than science. It's about anticipating what could go wrong and methodically preparing for it. By implementing the practices we've discussed – from idempotent task design to comprehensive monitoring – you'll be well-equipped to handle the complexities of distributed systems.
Key Takeaways
- Develop atomic and repeatable tasks to prevent data corruption when rerunning;
- Configure strategic retry mechanisms to handle temporary service interruptions;
- Utilize extensive monitoring tools to capture errors as soon as possible;
- Set up notifications for critical errors, ensuring prompt response;
- Employ task_always_eager to simplify testing and debugging.
Remember, it's not just about writing code that works; it's about crafting solutions that gracefully recover from the inevitable stumbles. Whether you're dealing with network hiccups or system crashes, these battle-tested strategies will help ensure your async tasks remain reliable and maintainable in production environments. Building robust async architectures is a journey – if you're looking to strengthen your Celery foundations, our Django + Celery articles are the perfect next step.










